il mondo può entrare qui!
qui, ma non solo qui, possono trovare posto le tue idee, i tuoi contenuti. Contattaci.
Il genoma umano
La cellula è l’unità costitutiva più piccola di ogni organismo multicellulare e può essere prodotta soltanto in seguito a divisione cellulare di un’altra cellula. Il corpo umano è formato approssimativamente da 6 × 1013 cellule di circa 320 tipi diversi. Pur avendo forma e funzioni differenziate le diverse cellule dell’organismo umano e, in generale, di tutti gli animali, possiedono, tranne poche ma importanti eccezioni, la stessa struttura: membrana, citoplasma e organelli a esso associati, e nucleo.
Il genoma umano è quindi costituito da due tipologie di materiale genetico: il DNA nucleare e il DNA mitocondriale.
(Chiara Turchi (2010) II genoma umano. In: Introduzione alla genetica forense. Springer, Milano)
Il 26 giugno del 2000 l’allora presidente statunitense Bill Clinton e il primo ministro inglese Tony Blair annunciavano congiuntamente che la prima “bozza” di genoma umano era stata generata. Il genoma umano era stato interamente mappato per la prima volta nella storia. Il risultato era di quelli epocali: si sarebbero spalancate le porte a nuovi studi per comprendere la nostra fisiologia, la nostra evoluzione, per curare malattie con una forte componente genetica. Nature nel febbraio 2001 pubblicò i dati prodotti dal consorzio internazionale Human genome project (Hgp), lanciato nel 1990 e finanziato per oltre 3 miliardi di dollari principalmente dal Nih (National institute of health) e dal dipartimento dell’energia del governo statunitense. Science invece pubblicò i risultati di un’azienda privata che nel 1998 aveva lanciato un progetto analogo e parallelo: era la Celera Genomics di Craig Venter. Il sequenziamento del genoma umano fu poi completato dallo Human Genome Project il 14 aprile 2003 e pubblicato nell’ottobre 2004, mentre nel maggio 2006 Nature pubblicava la sequenza dell’ultimo cromosoma, il cromosoma 1, il più lungo delle 23 coppie di cromosomi presenti nei nuclei delle nostre cellule: contiene infatti circa 249 milioni di nucleotidi, l’8% del nostro DNA totale.
I nucleotidi (G=guanina, A=adenina, C=citosina, T=timina; l’Rna contiene U=uracile al posto di T) sono le “lettere” che formano le istruzioni per far funzionare il nostro organismo e si danno in coppia: G sta C e A sta con T (o con U). Il nostro DNA conta più di 3 miliardi di coppie di basi nucleotidiche.
Alcune sequenze di lettere vengono chiamate geni. Ciò che caratterizza un gene è “avere una funzione”. Si dice infatti che i geni “codificano per una proteina”, ovvero esprimono le istruzioni per costruire i mattoncini fondamentali del nostro corpo, le proteine appunto, le unità funzionali del nostro organismo che svolgono i più svariati compiti, dalle funzioni metaboliche al trasporto di molecole da un luogo all’altro.
Un recente studio, pubblicato online su bioarXiv, si è occupato di rifare la conta dei geni umani, fissando a 21.306 il numero di geni codificanti per proteine. Lo stesso studio trova anche che sono altrettante, 21.856, le sequenze di DNA che non codificano per proteine. La porzione di DNA non codificante è però enormemente più vasta, in termini di numero di paia di basi, rispetto a quella codificante: 98% il DNA non codificante, 2% quello codificante. Che ruolo svolge dunque questa larghissima porzione di DNA “non funzionale”?
In gergo viene chiamata junk DNA e tutti gli organismi del regno animale ce l’hanno. Il termine fu coniato dal genetista Susumu Ohno nel 1972 per indicatre quelle sequenze che non codificano per proteine e caratterizzate da segmenti di lettere che si ripetono casualmente nel genoma. Molti di questi segmenti si sono generati per opera dei trasposoni, tratti di DNA che, nel corso della trascrizione, saltano da un posto all’altro del genoma, operando uncopia e incolla genetico. A lungo questo DNA “spazzatura” ha goduto di pessima fama ed è stato ignorato dai ricercatori, fino almeno agli anni ’90. Oggi si sa che le regioni di DNA non codificante, junk DNA, rappresentano una preziosa risorsa per il genoma, una sorta di magazzino da cui andare ad attingere materiale che consente la ricombinazione genetica, una delle fonti principali di mutazioni genetiche e di novità evolutive.
Ecco dunque il ruolo del DNA non codificante: oltre talvolta a interagire con quello codificante svolgendo compiti “regolatori” o “strutturali” nelle operazioni di trascrizione (funzioni epigenetiche), costituisce un’importante riserva di materiale genetico.
Il riciclo è uno dei meccanismi fondamentali della natura e questo principio vale anche per l’evoluzione. Un genoma è un’entità viva che cambia nel corso del tempo. Anche noi essere umani non siamo altro che variazioni sul tema di organismi che prima di noi hanno accumulato materiale genetico, che hanno usato queste sequenze di DNA per sopravvivere e vivere nella loro nicchia ecologica e che hanno sviluppato nuove mutazioni. Alcune di queste sono state selezionate positivamente, cioè impiegate nel gioco della vita; altre mutazioni sono state eliminate nel corso delle generazioni; e altre ancora, molte, semplicemente sono state messe in soffitta. Di spazio fortunatamente ce n’è e chi lo sa, un domani, come potranno tornare utili.
(Francesco Suman – Il Bo LIVE – 2018 – Università di Padova)
Evoluzione
Studi di genomica comparata sui genomi dei mammiferi suggeriscono che all’incirca il 5% del genoma umano si è conservato durante l’evoluzione a partire dalla divergenza avvenuta tra queste specie approssimativamente 200 milioni di anni fa. Questa porzione conservata contiene un’ampia maggioranza di geni e sequenze regolatrici. Intrigantemente, dal momento che geni e sequenze regolatrici rappresentano probabilmente meno del 2% del genoma, questo suggerisce che possano esserci più sequenze funzionali sconosciute che conosciute. Una frazione più piccola, ma comunque ampia, di geni umani sembra essere condivisa tra la maggior parte dei vertebrati analizzati.
Il genoma dello scimpanzé è per il 98.77% identico a quello umano. In media, un gene codificante una proteina in un uomo differisce dal suo ortologo nello scimpanzé per solo due sostituzioni aminoacidiche; quasi un terzo dei geni umani ha esattamente la stessa traduzione proteica dei loro ortologhi nello scimpanzé. Una grande differenza tra i due genomi è rappresentata dal cromosoma 2 umano, che è il prodotto della fusione dei cromosomi 12 e 13 dello scimpanzé.
La specie umana ha subito una massiccia perdita di recettori olfattivi durante la sua recente evoluzione e ciò può spiegare perché il nostro senso dell’olfatto sia approssimativo rispetto a quello della maggioranza dei mammiferi. Prove evolutive suggeriscono che lo sviluppo della visione dei colori nell’uomo e in diversi altri primati possa aver ridotto il bisogno del senso dell’olfatto.
Genoma mitocondriale
Il genoma mitocondriale umano è di grande interesse per i genetisti, dal momento che esso gioca indubbiamente un ruolo importante nelle malattie genetiche mitocondriali. Inoltre, esso è in grado di chiarificare alcuni punti “oscuri” dell’evoluzione umana; per esempio, l’analisi della variabilità del genoma mitocondriale umano ha portato a ipotizzare un recente comune antenato per tutti gli uomini lungo la linea di discendenza materna. (vedi Eva mitocondriale)
A causa della mancanza di un sistema di controllo degli errori di copiatura, il DNA mitocondriale (mtDNA) mostra un tasso maggiore di variazione rispetto al DNA nucleare. Questo aumento di circa 20 volte nel tasso di mutazione consente l’utilizzo del mtDNA come strumento per risalire con miglior accuratezza all’antenato materno. Studi del mtDNA nelle popolazioni hanno permesso di tracciare gli antichi flussi migratori, come la migrazione degli Indiani d’America dalla Siberia o dei Polinesiani dall’Asia sud-orientale. È stato inoltre utilizzato per dimostrare che c’è traccia del DNA dell’uomo di Neanderthal nel genoma dell’uomo europeo che condivide l’1-4% del genoma.
(Wikipedia)
Differenze tra dna e rna
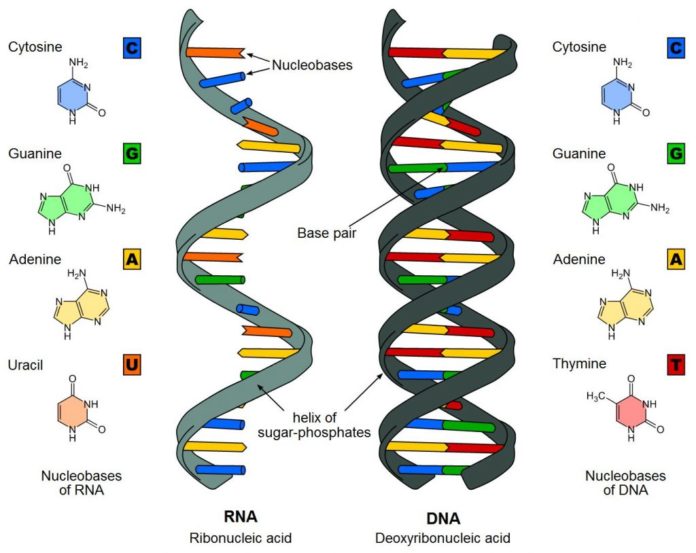
Il DNA e l’RNA sono acidi nucleici.
Gli acidi nucleici sono macromolecole presenti nel nucleo delle cellule, formati dalla combinazione di unità dette nucleotidi.
Ogni nucleotide è costituito da tre componenti:
- un gruppo fosfato;
- uno zucchero a 5 atomi di carbonio;
- una base azotata.
Nel DNA (o acido desossiribonucleico) lo zucchero è il desossiribosio e le quattro basi azotate sono: adenina (A), guanina (G), citosina (C), timina (T).
Nell’RNA (o acido ribonucleico) lo zucchero è il ribosio; come nel DNA, può essere legato a quattro basi azotate differenti: tre sono comuni al DNA (adenina, guanina e citosina), la quarta è differente e si chiama uracile (U).
Il DNA ha la forma di un’elica a doppio filamento; l’RNA presenta un filamento singolo.
Il DNA è presente nel nucleo di tutte le cellule ed è il depositario dell’informazione genetica. L’RNA si trova sia nel nucleo sia nel citoplasma delle cellule e partecipa direttamente alla sintesi delle proteine e alla trasmissione delle informazioni contenute nel DNA.
Nella cellula sono presenti tre tipi di RNA: l’RNA messaggero (mRNA), l’RNA ribosomiale (rRNA), l’RNA di trasporto (tRNA).
Nel 1957 Francis Crick enunciò il dogma centrale della biologia molecolare, che afferma che l’informazione “fluisce” dal DNA a una molecola di RNA e dalla molecola di RNA alla proteina.
(da studiarapido.it)